
前言
本文为书生·浦语大模型实战营的课程笔记系列第三节
LLM的局限性
- 知识时效性受限:如何让LLM能够获取最新的知识
- 专业能力有限:如何打造垂域大模型
- 定制化成本高:如何打造个人专属的LLM应用
大模型开发范式
解决局限性问题的两种方式是:
1. RAG
RAG: Retrieval Augmented Generation,使用外挂数据库,检索相关知识增强生成结果,特点:
- 低成本
- 可实时更新
- 受基座模型影响大
- 单次回答知识有限
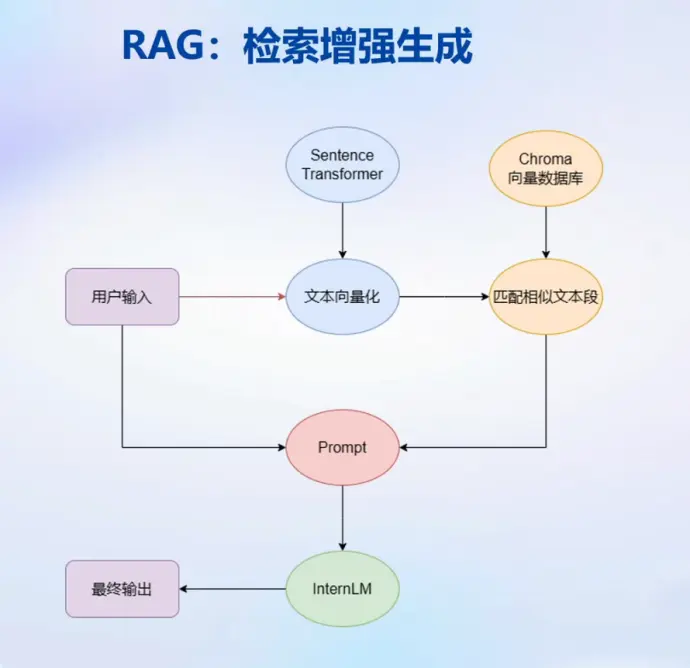
- 流程
- 输入文本转化为向量
- 在向量数据库中匹配相似文本
- 作为prompt在大模型中寻找答案
2. Finetune
也即通称的微调,特点:
- 可个性化微调
- 知识覆盖面广
- 成本高昂
- 无法实时更新
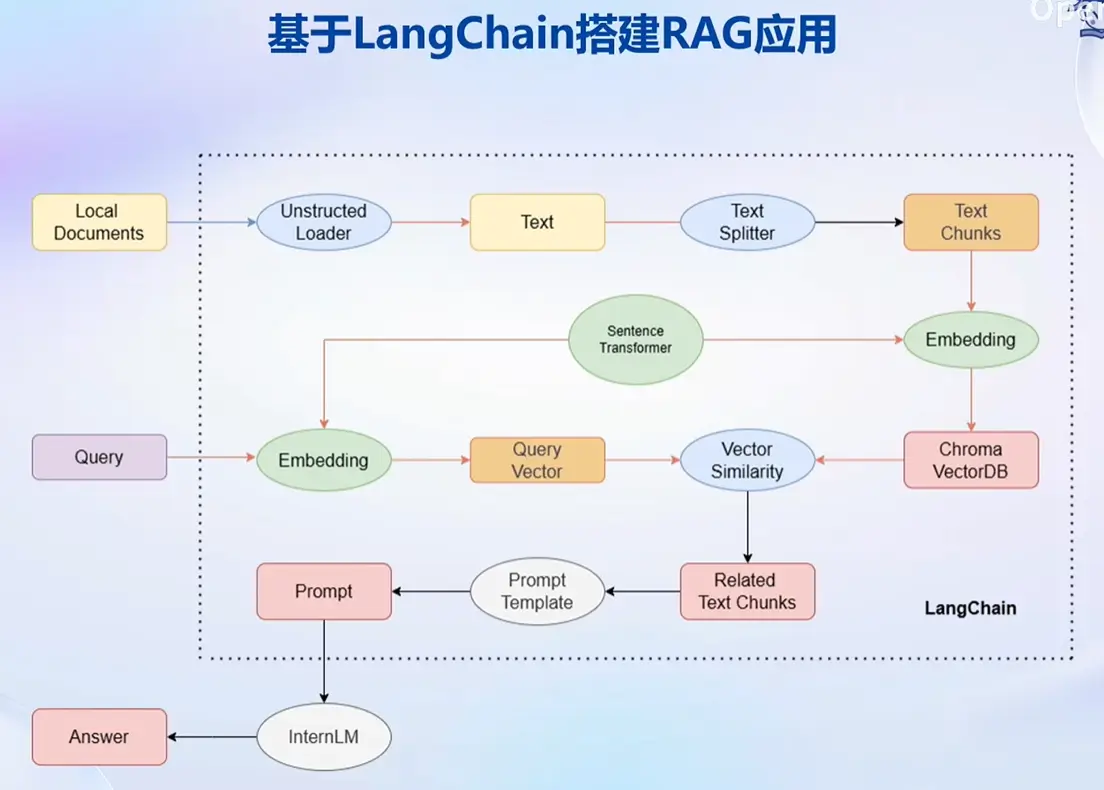
基于 LangChain 搭建 RAG 应用
LangChain框架简介
LangChain 框架是一个开源工具,通过为各种 LLM 提供通用接口来简化应用程序的开发流程,帮助开发者自由构建 LLM 应用。
LangChain 的核心组成模块:
- 链 (Chains) :将组件组合实现端到端应用,通过一个对象封装实现一系列LLM操作
- Eg. 检索问答链,覆盖实现了 RAG (检索增强生成)的全部流程
构建向量数据库
加载源文件
- 确定源文件类型,针对不同类型的源文件选用不同的加载器
- 核心在于将带格式的文本转化为无格式的字符串
文档分块
- 由于单个文档往往超过模型上下文上限,我们需要对加载的文档进行切分
- 一般按字符串长度进行分割
- 可以手动控制分割块的长度和重叠区间长度
文档向量化
- 使用向量数据库来支持语义检索,需要将文档向量化存入向量数据库
- 可以使用任意一种 Embedding 模型来进行向量化
- 可以使用多种支持语义检索的向量数据库,一般使用轻量级的 Chroma
搭建知识库助手
将 InternLM 接入 LangChain
- LangChain 支持自定义 LLM,可以直接接入到框架中
- 我们只需将 InternLM 部署在本地,并封装一个自定义 LLM 类,调用本地 InternLM 即可
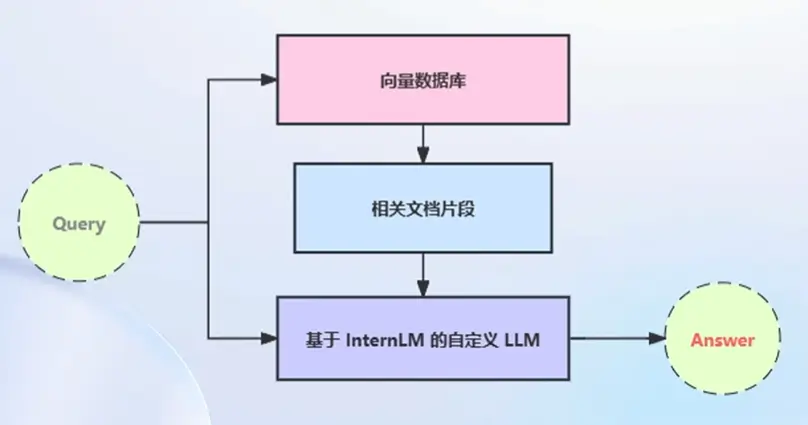
构建检索问答链
- LangChain 提供了检索问答链模版,可以自动实现知识检索、Prompt 嵌入、LLM 问答的全部流程
- 将基于 InternLM 的自定义 LLM 和已构建的向量数据库接入到检索问答链的上游
- 调用检索问答链,即可实现知识库助手的核心功能
RAG 方案优化建议
- 基于RAG的问答系统性能核心受限于:
- 检索精度
- Prompt性能
- 一些可能的优化点:
- 检索方面:
- 基于语义分割,保证每一个chunk的语义完整
- 给每一个chunk生成概括式索引,检索时匹配索引
- Prompt方面
- 迭代优化Prompt策略
- 检索方面:
作业
基础作业
目标:复现课程知识库助手搭建过程 (截图)
环境配置
本次沿用上节课程配置的 InternStudio 平台开发机,省去了一些环境准备的时间,过程不再赘述,教学文档中有详细步骤。
构建向量数据库
- 终端命令:

Web Demo
- 终端命令:

- 结果图:

- 分析:从结果来看,大模型回答出了有关23年12月的问题,这不在它本身训练数据中,证明检索问答链是有效的。
进阶作业
目标:选择一个垂直领域,收集该领域的专业资料构建专业知识库,并搭建专业问答助手,并在 OpenXLab 上成功部署(截图,并提供应用地址)
由于时间关系,进阶作业没有计划做