
前言
本文为书生·浦语大模型实战营的课程笔记系列第四节
- 教学视频:B站 BV1yK4y1B75J
- 配套文档:InternLM/tutorial xtuner
Finetune简介
LLM 的下游应用中,增量预训练和指令跟随是经常会用到的两种微调模式

增量预训练微调
- 使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识
- 训练数据:文章、书籍、代码等
- 数据构成:没有
System和Input,只有Output,全部参与loss计算
指令跟随微调
- 使用场景:让模型学会对话模板,根据人类指令进行对话
- 训练数据:高质量的对话、问答数据
- 数据构成:包含
System、Input和Output,但只有Output部分参与loss计算
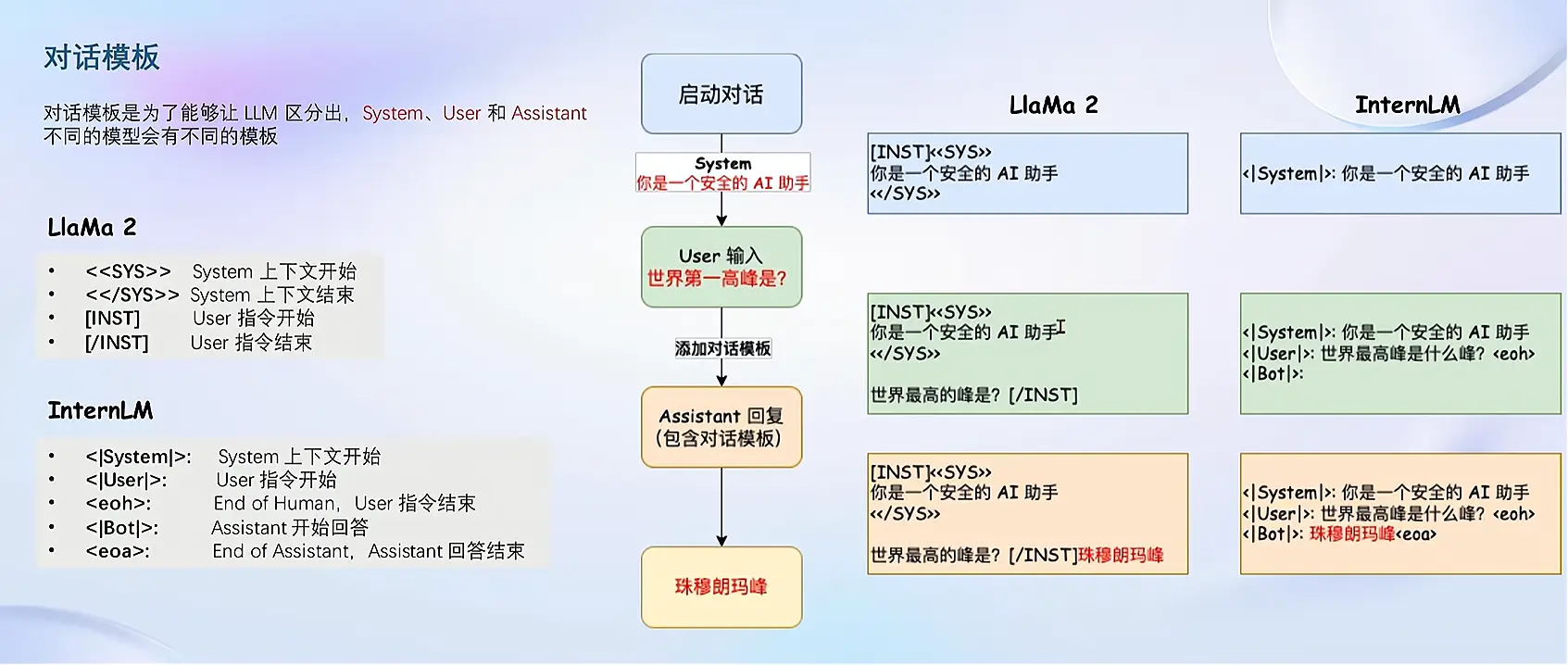
对话模板
- 对话模板是为了能够让 LLM 区分出 System、User 和 Assistant
- 不同的模型会有不同的模板
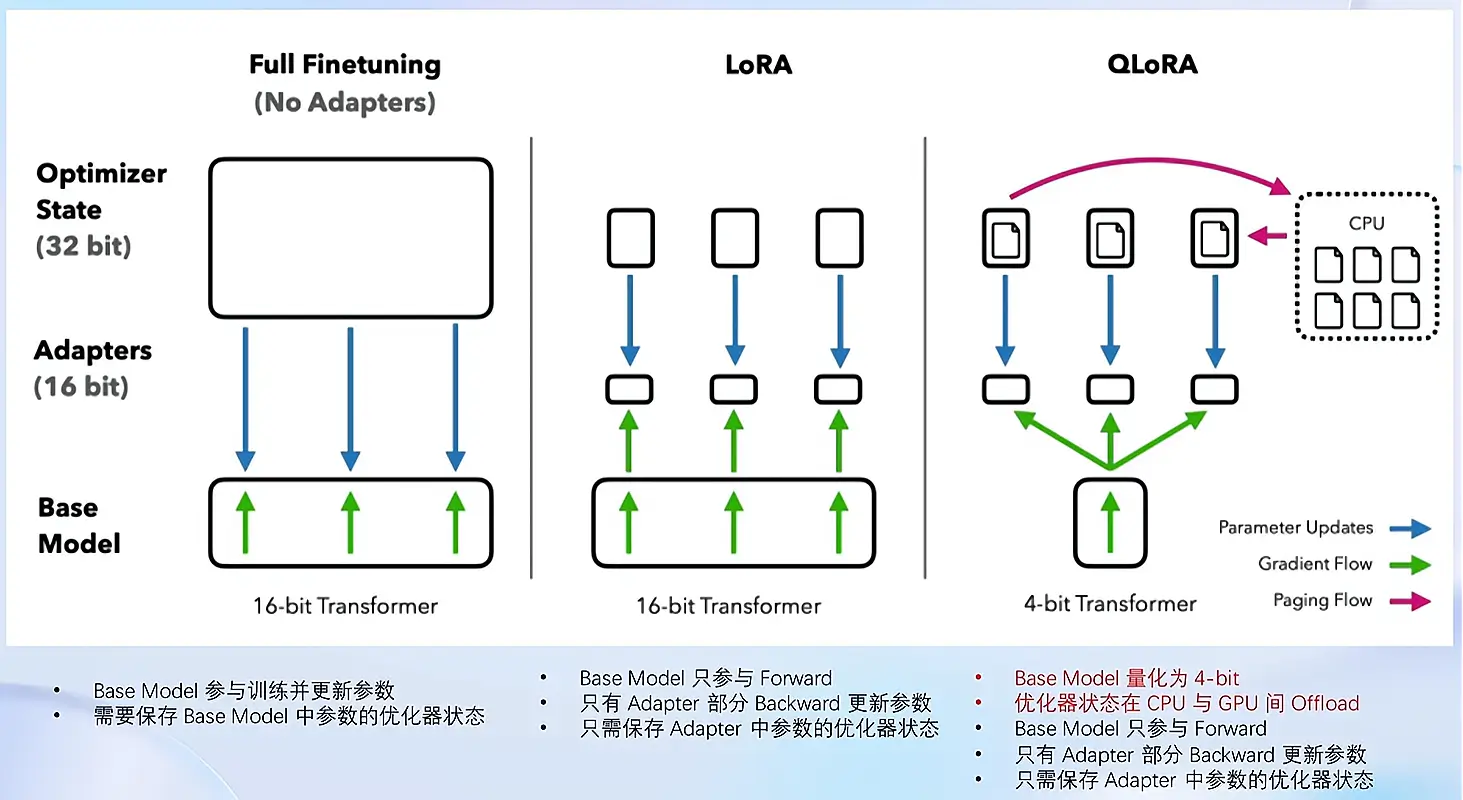
LoRA & QLoRA
LoRA: Low-Rank Adaptation of Large Language Models
- LLM 的参数量主要集中在模型中的 Linear, 训练这些参数会耗费大量的显存
- LoRA 通过在原本的 Linear 旁,新增一个支路,包含两个连续的小 linear,新增的这个支路通常叫做 Adapter
- Adapter 参数量远小于原本的 Linear,能大幅降低训练的显存消耗
QLoRA: Quantized LLMs with Low-Rank Adapters
- 4位NormalFloat量化:这是一种改进量化的方法,确保每个量化仓中有相同数量的值,这避免了计算问题和异常值的错误。
- 双量化:对量化常量再次量化以节省额外内存的过程。
- 统一内存分页:它依赖于NVIDIA统一内存管理,自动处理CPU和GPU之间的页到页传输,它可以保证GPU处理无错,特别是在GPU可能耗尽内存的情况下。
全量微调、LoRA、QLoRA对比
XTuner简介
详见 XTuner 的官方仓库
XTuner快速上手
参考配套教学文档:InternLM/tutorial xtuner
自定义微调数据
按照教学文档,实操一遍即可,XTuner 上手确实很简单
MS-Agent 数据集
这个数据集比较有意思,能够赋予大模型调用api的agent能力,原理:
- 模型的回复中会包括插件调用代码和执行代码
- 调用代码是 LLM 生成的
- 执行代码是需要调用服务来生成结果的,这里我们需要给
xtuner chat增加--lagent参数来实现
lagent调用实战
本次继续沿用之前课程配置的 InternStudio 平台开发机
| |
测试验证
prompt: 你好,西安明天天气怎么样?
- 结果图:
- 教学视频里回答失败了,但我自己部署是成功的

作业
基础作业
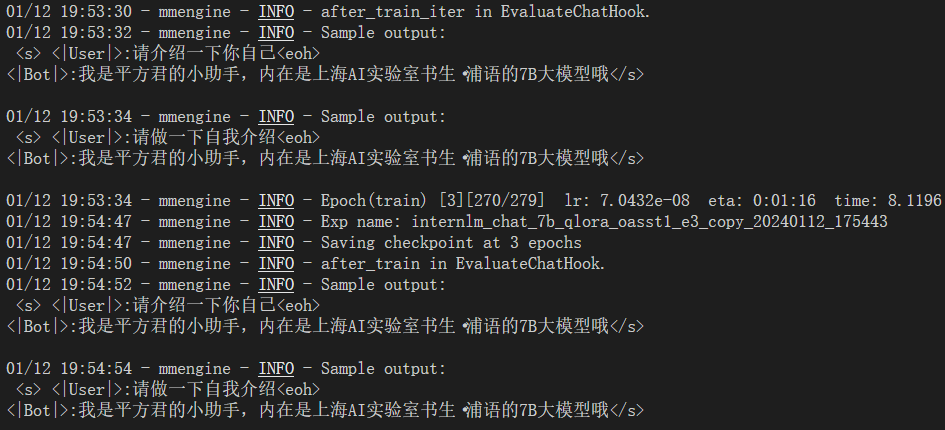
目标:构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手,效果如下图所示,本作业训练出来的模型的输出需要将不要葱姜蒜大佬替换成自己名字或昵称!
作业参考文档: XTuner InternLM-Chat 个人小助手认知微调实践
- 训练最后的 eval chat结果已经有变化了:
- Web Demo 结果图:
- 其中前3条是我给的训练数据,后面两条是模型自己学习到的

进阶作业
目标:
- 将训练好的Adapter模型权重上传到 OpenXLab、Hugging Face 或者 MoelScope 任一一平台。
- 将训练好后的模型应用部署到 OpenXLab 平台,参考部署文档请访问:https://aicarrier.feishu.cn/docx/MQH6dygcKolG37x0ekcc4oZhnCe
由于时间关系,进阶作业没有计划做