
前言
本文为书生·浦语大模型实战营的课程笔记系列第五节
大模型部署背景
模型部署
- 定义
- 将训练好的模型在特定软硬件环境中启动的过程,使模型能够接收输入并返回预测结果
- 为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩和硬件加速
- 产品形态
- 云端、边缘计算端、移动端
- 计算设备
- CPU、GPU、NPU、TPU 等
大模型特点
- 内存开销巨大
- 庞大的参数量。7B模型仅权重就需要 14+G 内存
- 采用自回归生成 token,需要缓存 Attention 的 k/v,带来巨大的内存开销
- 动态 shape
- 请求数不固定
- Token 逐个生成,且数量不定
- 相对视觉模型,LLM 结构简单
- Transformers 结构,大部分是 decoder-only
大模型部署挑战
- 设备
- 如何应对巨大的存储问题?低存储设备(消费级显卡、手机等)如何部署?
- 推理
- 如何加速 token 的生成速度
- 如何解决动态 shape,让推理可以不间断
- 如何有效管理和利用内存
- 服务如何提升系统整体吞吐量?
- 对于个体用户,如何降低响应时间?
大模型部署方案
- 技术点
- 模型并行
- 低比特量化
- Page Attention
- transformer 计算和访存优化
- Continuous Batch
- …
- 方案
- huggingface transformers
- 专门的推理加速框架
- 云端
- lmdeploy
- vllm
- tensorrt-llm
- deepspeed
- …
- 移动端
- llama.cpp
- mlc-llm
- …
- 云端
LMDeploy 简介
LMDeploy 是 LLM 在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务。项目地址: https://github.com/InternLM/lmdeploy
LMDeploy 提供以下核心功能(细节详见官方仓库,这里不做赘述):
- 高效推理引擎 TurboMind:开发了 Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性,保障了 LLMs 推理时的高吞吐和低延时。
- 有状态推理:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。
- 量化:LMDeploy 支持多种量化方式和高效的量化模型推理。在不同规模的模型上,验证了量化的可靠性。
动手实践环节——安装、部署、量化
跟着教学配套文档:InternLM/tutorial lmdeploy 一步一步跟下来即可
作业
基础作业
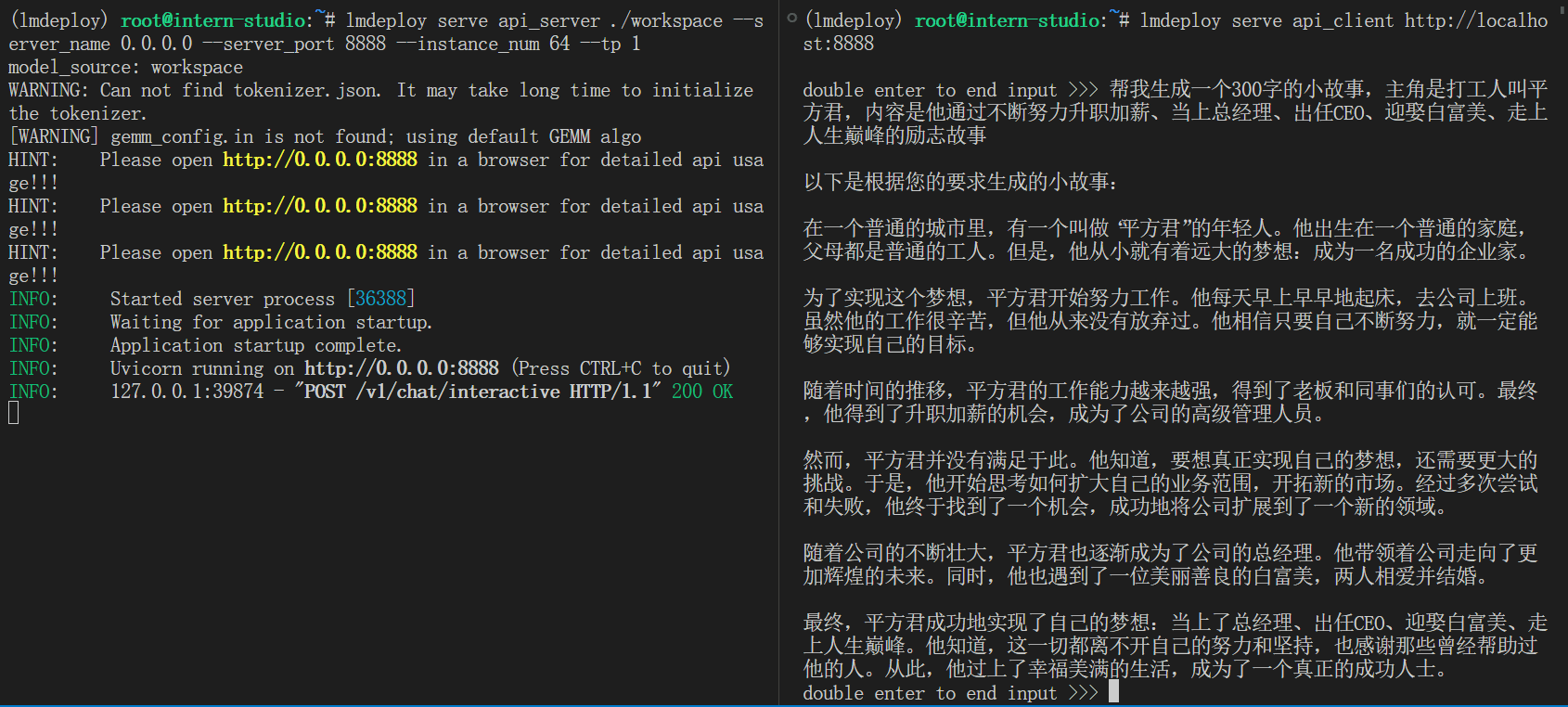
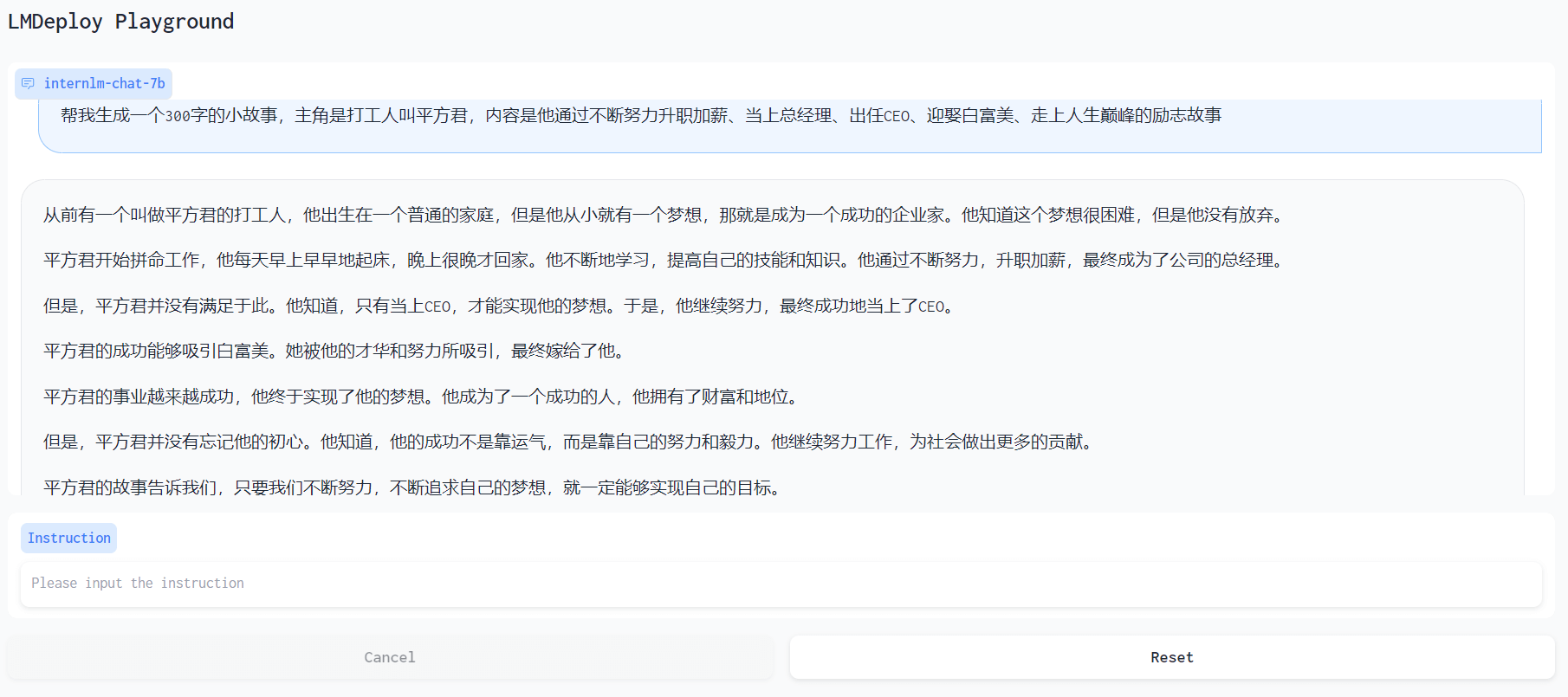
目标:使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图)
作业很简单,只需要几条命令即可,索性3种方式都来一遍,操作流程:
| |
使用的prompt:帮我生成一个300字的小故事,主角是打工人叫平方君,内容是他通过不断努力升职加薪、当上总经理、出任CEO、迎娶白富美、走上人生巅峰的励志故事
- 本地对话结果:

- API服务结果:
- 网页Gradio结果:
进阶作业(可选做)
目标:
- 将第四节课训练自我认知小助手模型使用 LMDeploy 量化部署到 OpenXLab 平台。
- 对internlm-chat-7b模型进行量化,并同时使用KV Cache量化,使用量化后的模型完成API服务的部署,分别对比模型量化前后和 KV Cache 量化前后的显存大小(将 bs设置为 1 和 max len 设置为512)。
- 在自己的任务数据集上任取若干条进行Benchmark测试,测试方向包括:
(1)TurboMind推理+Python代码集成
(2)在(1)的基础上采用W4A16量化
(3)在(1)的基础上开启KV Cache量化
(4)在(2)的基础上开启KV Cache量化
(5)使用Huggingface推理
由于时间关系,进阶作业没有计划做